L3DAS22 dataset details
The dataset for both tasks shares a common basis: the recording environment and the techniques adopted during it.
We sampled the acoustic field of a large office room with the approximate dimensions of 6 m (length) by 5 m (width) by 3 m (height). The room has typical office furniture: desks, chairs and a wardrobe.
We placed two first-order A-format Ambisonics microphones in the center of the room and we moved a speaker reproducing an analytic signal in 252 fixed spatial positions.
One microphone (mic A) lies in the exact center of the room, shown as a red sphere/dot, and the other (mic B) is 20 cm distant towards the width dimension.

Recording procedure
The speaker placement is performed according to two different criteria: a fixed 3D grid (168 positions) and a 3D uniform random distribution (84 positions).
The first picture (left one on bigger screens) shows a 2D projection of the grid from above. For the first criterion,we placed the speaker in a 3D grid with a 50cm step in the length-width dimensions and 30 cm step in the height dimension. There are 7 position layers in the height dimension at 0.3 m, 0.7 m, 1 m,1.3 m, 1.6 m, 1.9 m, 2.3 m from the floor.
The random positions, instead, respect a uniform distribution and are quantized in a virtual 3d grid with a 25 cm step.
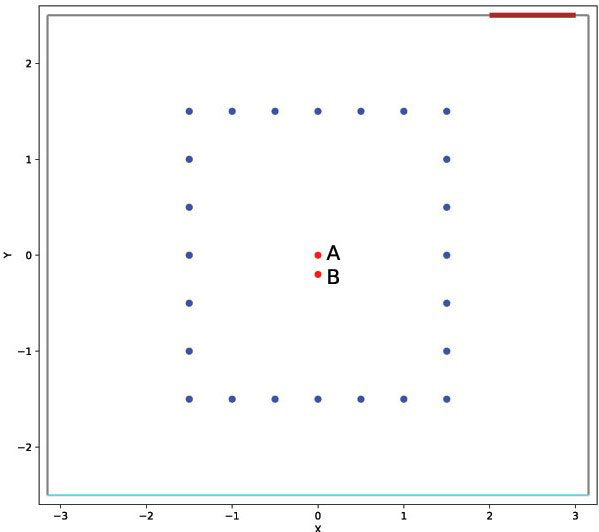
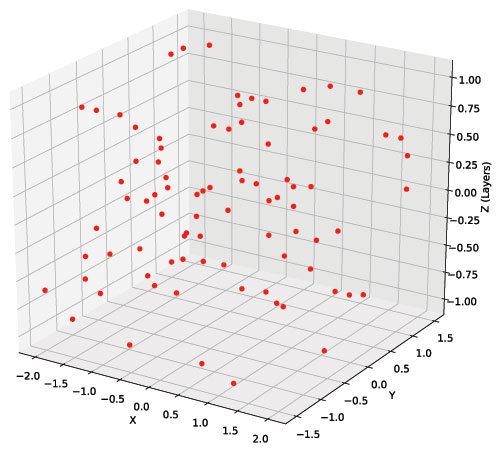
Each speaker position is identified by a tuple (X, Y, Z), where X is in the range [-2.0, +2.0], Y in [-1.5, +1.5] (both with a 0.25 step) and Z in [-1.0, +1.0] (with a 0.3 step from 0 and a last +/-0.4 step to reach the extremes). Therefore, Ambisonics microphone A is in the (0, 0, 0) position. All labels are consistent with this notation; elevation and azimuth are however easily obtainable.
The analytic signal we used is a 24-bit exponential sinusoidal sweep that glides from 50Hz to 16000Hz in 20 seconds, reproduced at 90 dB SPL on average. The IR estimation is then obtained by performing a circular convolution between the recorded sound and the time-inverted analytic signal, as introduced by Farina. We finally converted the A-format signals into standard B-format IRs.
The dataset is divided in two main sections, respectively dedicated to the challenge tasks. We provide normalized raw waveforms of all Ambisonics channels (8 signals in total) as predictors data for both sections, the target data varies significantly. Moreover, we created different types of acoustic scenarios, optimize for each specific task.
We split both dataset sections into: a training set (80 hours for SE and 5 hours for SELD) and a test set (7 hours for SE and 2.5 hours for SELD), paying attention to create similar distributions. The train set of the SE section is divided in two partitions: train360 and train100, and contain speech samples extracted from the correspondent partitions of Librispeech (only the sample up to 12 seconds). All sets of the SELD section are divided in: OV1, OV2, OV3. These partitions refer to the maximum amount of possible overlapping sounds, which are 1, 2 or 3, respectively.
Additional material
March 2023 update: We also release the impulse responses related to the 252 room positions and used to generate the L3DAS21 and L3DAS22 datasets. The impulsive responses, which can be downloaded from this link, are distrubuted under an Attribution 4.0 International (CC BY 4.0) license. Users are requested to cite the official L3DAS22 paper in their work.