Sound event classes
To generate the spatial sound scenes the computed IRs are convolved with clean sound samples belonging to distinct sound classes. The noise sound event database we used for task 1 is the well-known FSD50K dataset. In particular, we have selected 12 transient classes, representative of the noise sounds that can be heard in an office: computer keyboard, drawer open/close, cupboard open/close, finger snapping, keys jangling, knock, laughter, scissors, telephone, writing, chink and clink, printer, and 4 continuous noise classes: alarm, crackle, mechanical fan and microwave oven.
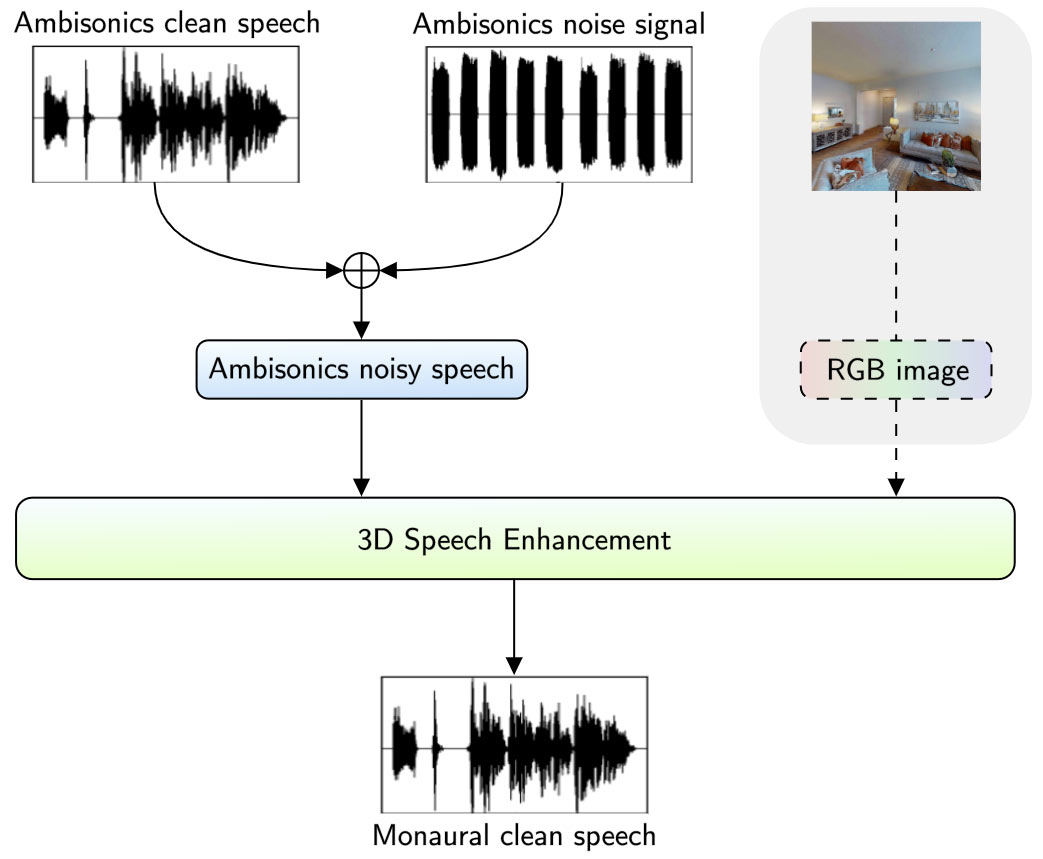
Furthermore, we extracted clean speech signals (without background noise) from Librispeech, taking only sound files up to 12 seconds.
Dataset specs
The main characteristics of the L3DAS23 Task1 section are:
- more than 4000 virtual 3D audio with a duration up to 12 seconds
- 16kHz 16 bit AmbiX wav files
- clean voice sounds from Librispeech
- up to 3 non-speech overlapping background noises
- 700+ RIRs positions for each microphone position in a selection of 68 virtual environments (300k+ possible RIRs positions)
- a total of nearly 90 hours of audio tracks
- one RGB image for each microphone position
The predictors data of this section are released as 8-channels 16kHz 16 bit wav files, consisting of 2 sets of first-order Ambisonics recordings (4 channels each). The channels order is [WA,YA,ZA,XA,WB,YB,ZB,XB], where A/B refers to the used microphone and WYZX are the b-format ambisonics channels. A csv file named audio_image.csv connects each audio to its respective image.
The dataset is organized as follows:
- L3DAS23_Task1_{train_clean_360, train_clean_100, dev_clean}
- data
- XXX-YYYYYY-ZZZZ_A.wav
- (first-order Ambisonics recording of mic A)
- XXX-YYYYYY-ZZZZ_B.wav
- (first-order Ambisonics recording of mic B)
- ...
- labels
- XXX-YYYYYY-ZZZZ.txt
- (Speech transcription)
- XXX-YYYYYY-ZZZZ.wav
- (Monaural clean speech)
- ...
- audio_image.csv
- (Csv where each line is a couple of the form: XXX-YYYYYY-ZZZZ,imagefilename.png)
- info.csv
- (Csv containing general information on each recording, such as: IR_ID, speaker position, distance of the speaker from mic A)